|
|
||
|---|---|---|
| .github | ||
| assets | ||
| generation | ||
| names_dataset | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
README.md
name-dataset
A Global Exhaustive First and Last Name Database
Features
- ~160k first names
- ~100k last names
- Find Names in Texts
- High Precision / Recall
- Worldwide Names
Installation
npm install name-dataset
The NPM package is not available yet, to be published shortly.
Usage
const Names = require('name-dataset')

How reliable is it?
Well, it depends if you are looking for a high recall or a high precision. For example, the word Rose can be either a name or a noun. If we include it in the list, then we increase the precision but we decrease the recall. And vice versa, if it's not in the list. The library checks that the word starts with a capital letter. In our case, we emphasize more on precision. So I would say the best use case here is to check whether it's a name or not based on a prior knowledge that the customer has submitted a name.
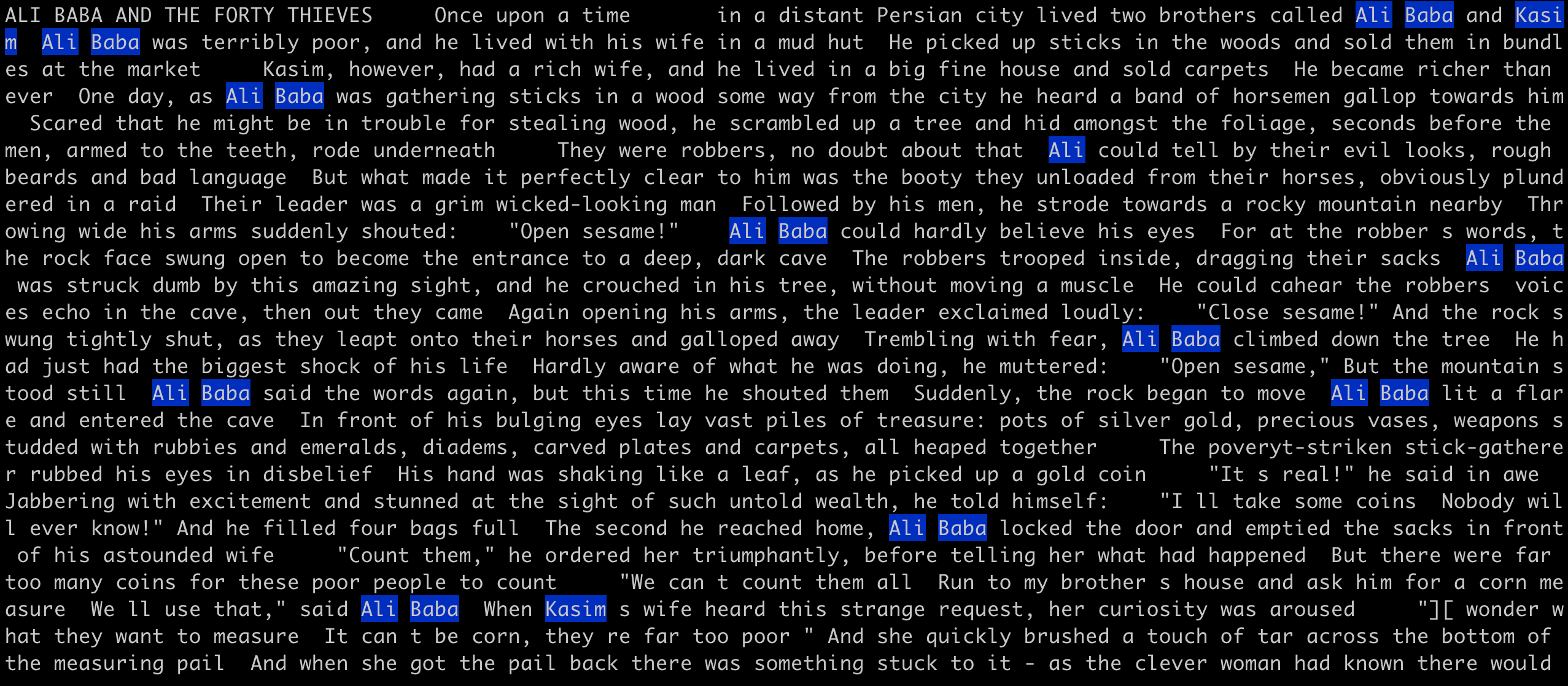
Here is an example on a (old) text: ALI BABA AND THE FORTY THIEVES.
Dataset Generation
- listofrandomnames.com
- sajari.com 5000 Names around the Globe
- 20000-names.com
- UK Gov Boys Names 100 Years
- UK Gov Girls Names Years
- Scotland Baby Names
- Open Gender Tracking
- bocoup.com Global Names
- MatthiasWinkelmann's Repo
- Namepedia
- Imdb Datasets
- Imdb Interfaces
- Stackenchange OpenData
- hiese.de Listings
- Data World
- Belgium Gov
- UK Gov Birth
- CMU AI Repo Corpora
- US Social Security Data Baby Names I
- US Social Security Data Baby Names II
- US Social Security Data Popular Names
- Hadley Repo Baby Names
- QuietAffiliate.com
- Stackoverflow
- Mbejda Repo
- US Gov Cencus
- Stackexchange Opendata Japanese
- Stackexchange Opendata Gender
- Stackexchange Opendata Country
- Randomnames.com Boys
- Wikipedia Popular Names
- USCS Female Names
- Oxford Reference
- dominctarr Repo
- smashew Repo
- Behind The Name
- Incompetech