|
|
||
|---|---|---|
| .github | ||
| assets | ||
| generation | ||
| names_dataset | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| evaluate.py | ||
| main.py | ||
| setup.py | ||
README.md
name-dataset
A First and Last Name Dataset
Features
- ~160k first names
- ~100k last names
- Find Names in Texts
- Hiigh Precision / Recall
- Worldwide Names
echo -e "$(python main.py 'Brian is in the kitchen while Amanda is watching the TV on the sofa.\nThey are both waiting for Alfred to come.')"

How reliable is it?
Well, it depends if you are looking for a high recall or a high precision. For example, the word Rose can be either a name or a noun. If we include it in the list, then we increase the precision but we decrease the recall. And vice versa, if it's not in the list. The library checks that the word starts with a capital letter. In our case, we emphasize more on precision. So I would say the best use case here is to check whether it's a name or not based on a prior knowledge that the customer has submitted a name.
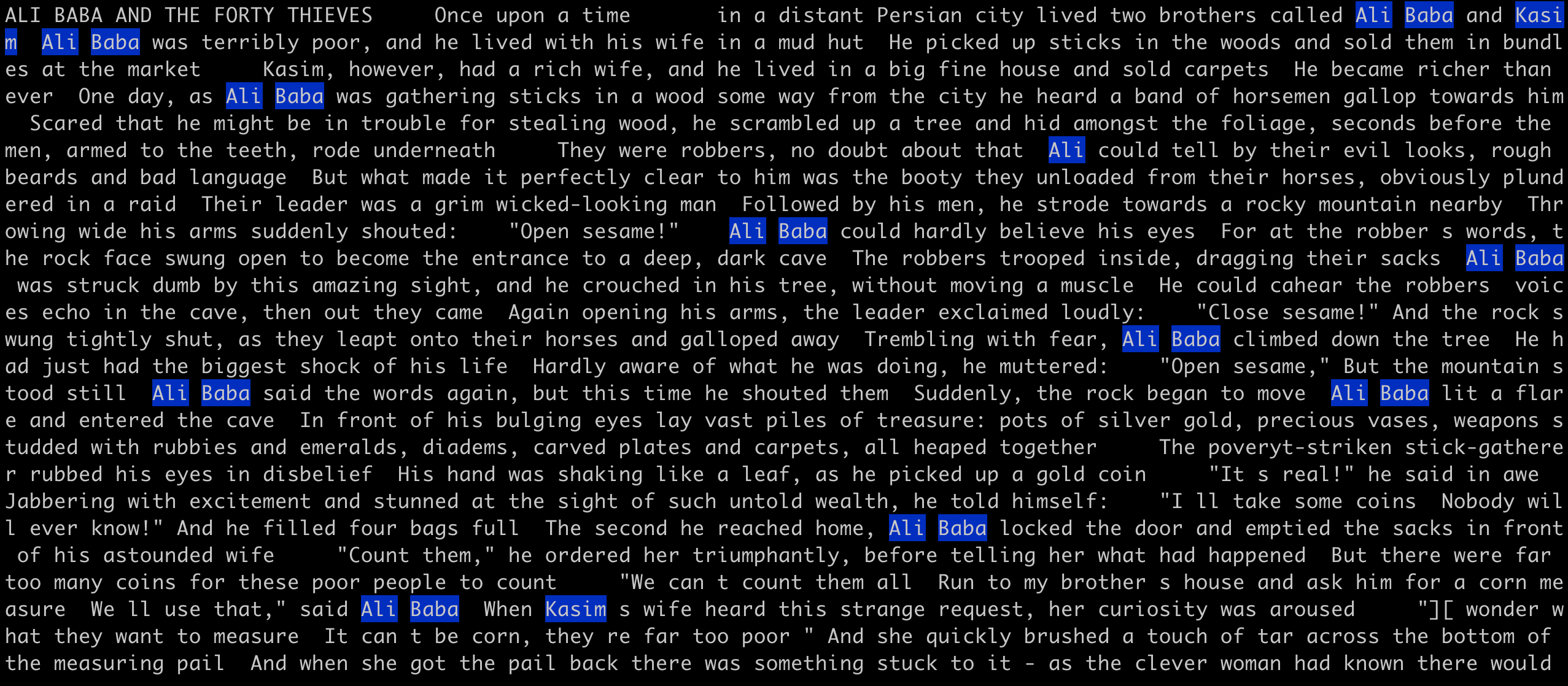
Here is an example on a (old) text: ALI BABA AND THE FORTY THIEVES.
License
I don't own the data obviously. It's fetched from the websites listed in:
https://github.com/philipperemy/name-dataset/blob/master/generation/generate.sh
So I guess the most strict software license should apply here.
Sources and References
Exhaustive list of all the possible websites. Not all are used since there is a lot of garbage in the lists.
-
https://www.sajari.com/public-data: 5000 names (First Names CSV)
-
http://www.20000-names.com/ names around the world
-
https://catalogue.data.gov.bc.ca/dataset/most-popular-boys-names-for-the-past-100-years UK
-
https://catalogue.data.gov.bc.ca/dataset/most-popular-girl-names-for-the-past-100-years UK
-
https://github.com/OpenGenderTracking/globalnamedata/tree/master/assets
-
ftp://ftp.heise.de/pub/ct/listings/0717-182.zip
-
https://statbel.fgov.be/en/open-data/first-names-total-population-municipality
-
http://www.cs.cmu.edu/afs/cs/project/ai-repository/ai/areas/nlp/corpora/names/
-
https://github.com/hadley/data-baby-names/blob/master/baby-names.csv
-
http://www.quietaffiliate.com/free-first-name-and-last-name-databases-csv-and-sql/
-
https://stackoverflow.com/questions/1452003/plain-computer-parseable-lists-of-common-first-names
-
https://www2.census.gov/topics/genealogy/1990surnames/dist.all.last
-
https://opendata.stackexchange.com/questions/12234/name-and-gender-dataset
-
https://opendata.stackexchange.com/questions/7071/people-names-by-country
-
https://en.wikipedia.org/wiki/List_of_most_popular_given_names#cite_note-ahram2004-2
-
https://github.com/dominictarr/random-name/blob/master/first-names.txt
-
https://github.com/smashew/NameDatabases/tree/master/NamesDatabases/first%20names